Adaptive Architecture
Today's distributed software systems are typically designed with just enough complexity to satisfy basic functional requirements. But for products designed for hyper-growth, non-functional requirements like performance and resource costs could become functional requirements at scale.
Note: This post is about distributed systems design
Contents
- Introduction
- An Example Problem
- An Adaptive Design Solution
- An Example Implementation
- Results
- Conclusion
1. Introduction
Today's distributed software systems are typically designed with just enough complexity to satisfy basic functional requirements. This approach makes sense because a simple initial design means shipping a product faster and cheaper, therefore reducing the short-term risk to market.
But for products designed for hyper-growth, non-functional requirements like performance and resource costs could become functional requirements at scale. And while performance related to internal design choices are easier to address down the road, it is those that depend on external factors such as vendors that may not become obvious until sometime later. That is why it is extremely important to invest in evaluating, benchmarking and testing external factors with more scrutiny as part of the discovery phase and before major dev investment has begun. Once identified, these cases may require thinking about an elastic design up-front as a way to scale product down the road.
There's a great talk by now-retired C++ expert, Scott Meyers, where he beautifully explains how Donald Knuth's famous quote "...premature optimization is the root of all evil.." has often been relayed by leaving out some crucial context. The quote was meant for the little optimizations in a system, not foundational system design.
2. An Example Problem
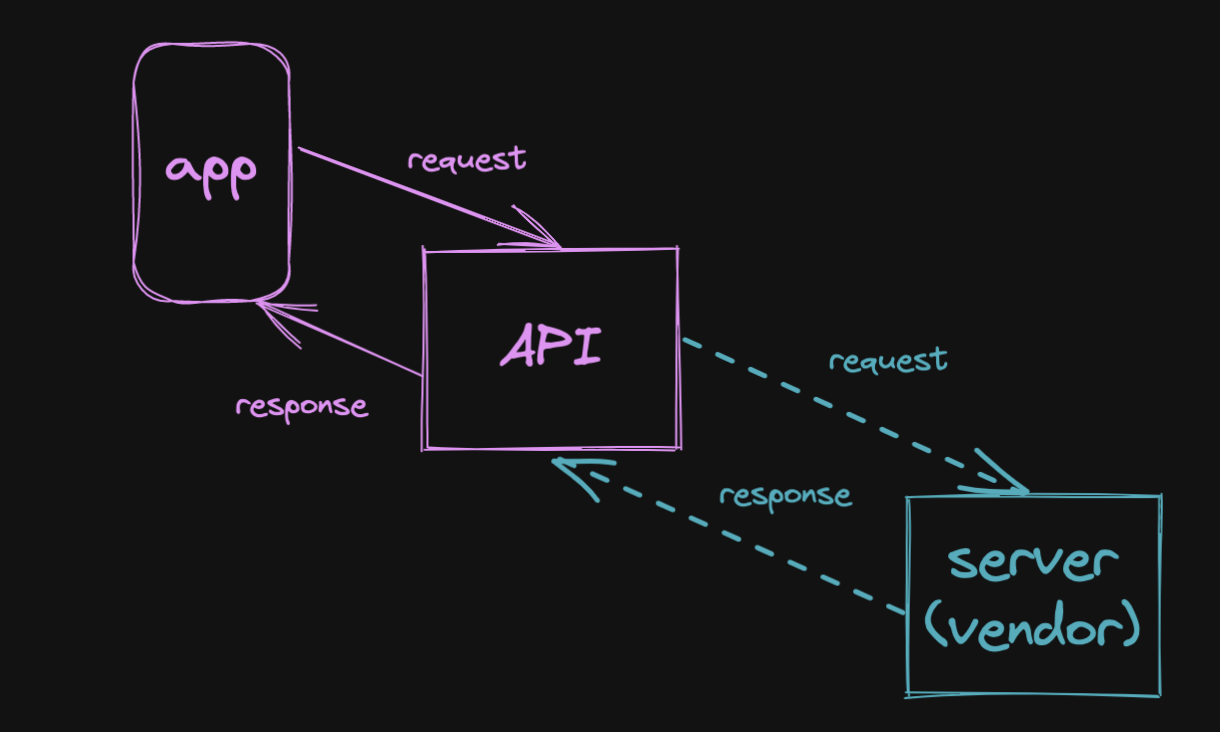
Let's illustrate this with a fictional problem. A team builds a software product consisting of an App and its backend API. The product will allow users to fetch the current balance of a digital wallet on demand so they can make a real time decision about something they want to buy.
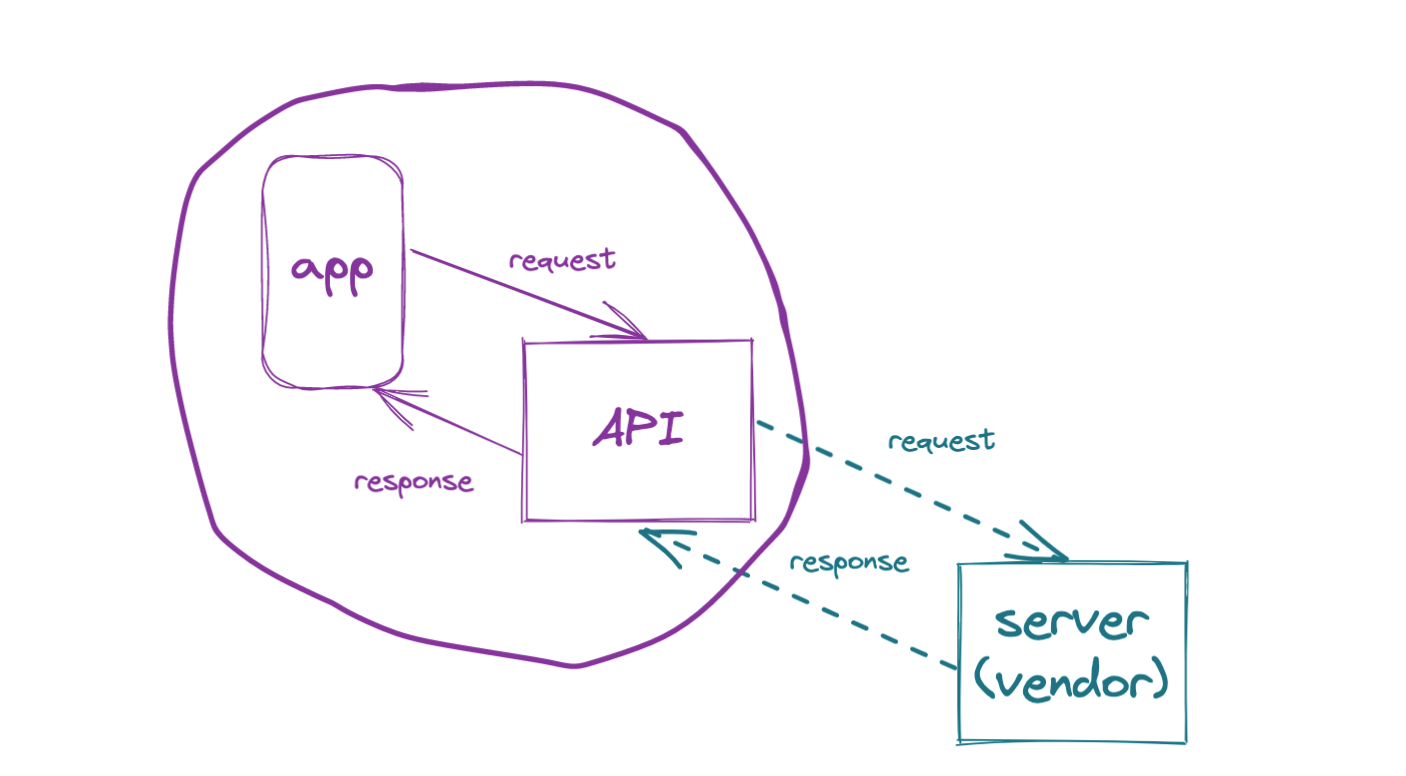
In order to fetch the wallet balance, the API must forward the request to a vendor's API which provides wallet access. In this scenario, the vendor is really the "server" and the client API is mostly a proxy.
Initial user experience studies show that most users will check their balance at lunch time and after work. Peak days will be Thu, Fri, and Sat. This means the largest number of API requests, and therefore, vendor API activity will also vary over time.
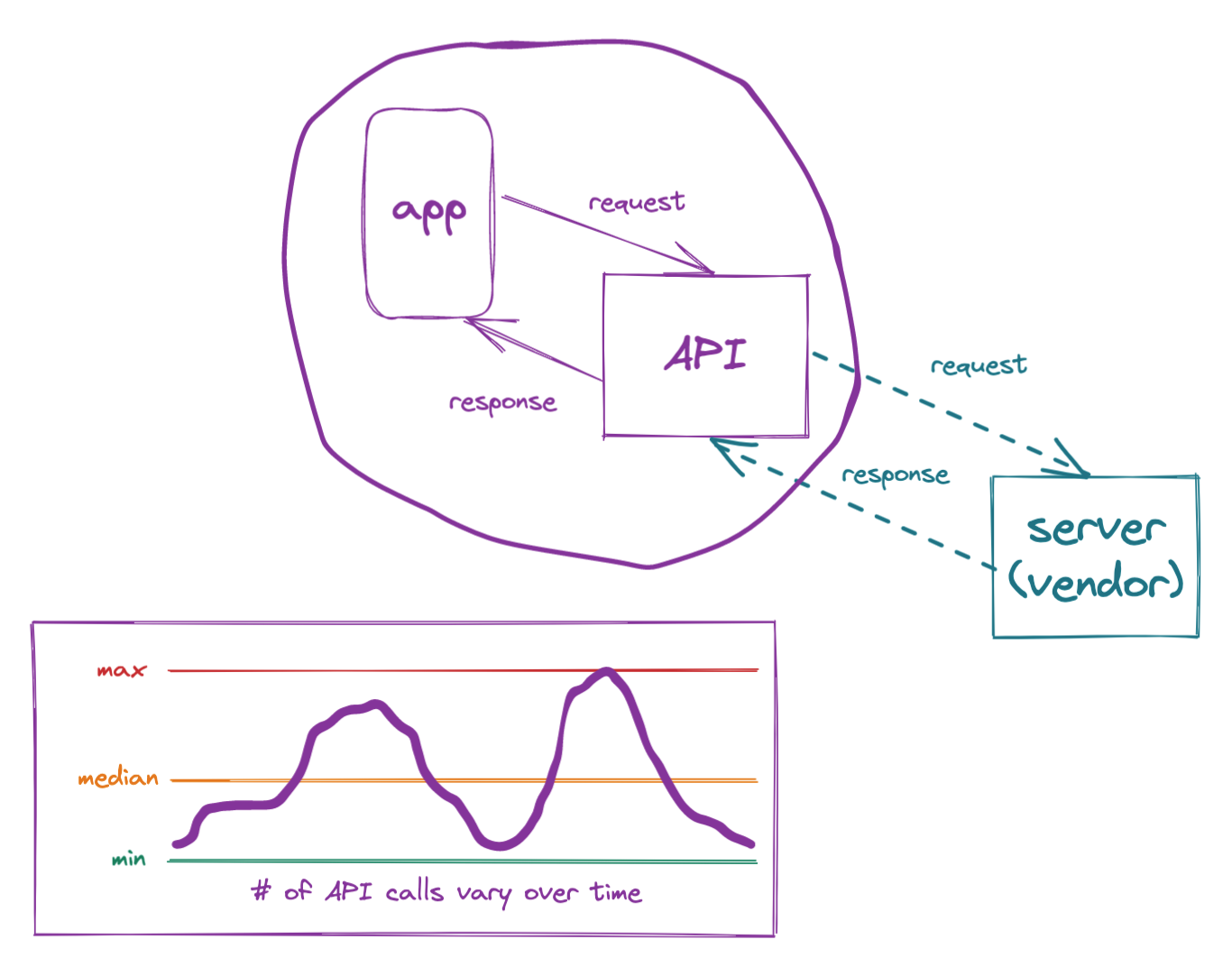
In addition, the product team concludes that the quality of user experience will be driven by two important factors:
- UI speed - which depends on vendor response time. Obviously, the client can cache server responses but won't solve for the next factor...
- Data accuracy - which depends on vendor's ability to resolve on-demand requests reliably
The product team projects technical benchmarks and speaks with the vendor which assures the team that the service will deliver what they need. Here's a recap of what the fictional contract looks like.
SLA Contract With Client. Vendor guarantees to
- support up to 100 client concurrent requests 99.95% of the time
- deliver a response time of 20ms for 99.95% of all client requests
- successfully respond to 99.95% of all valid client requests
Great. The team implements the integration and is ready to go to market. Then reality sets in. As the number of users grows, the team notices that the SLAs aren't always observed. The problem starts to get worse as the product becomes more popular. Certain user segments are hit even harder for unknown reasons.
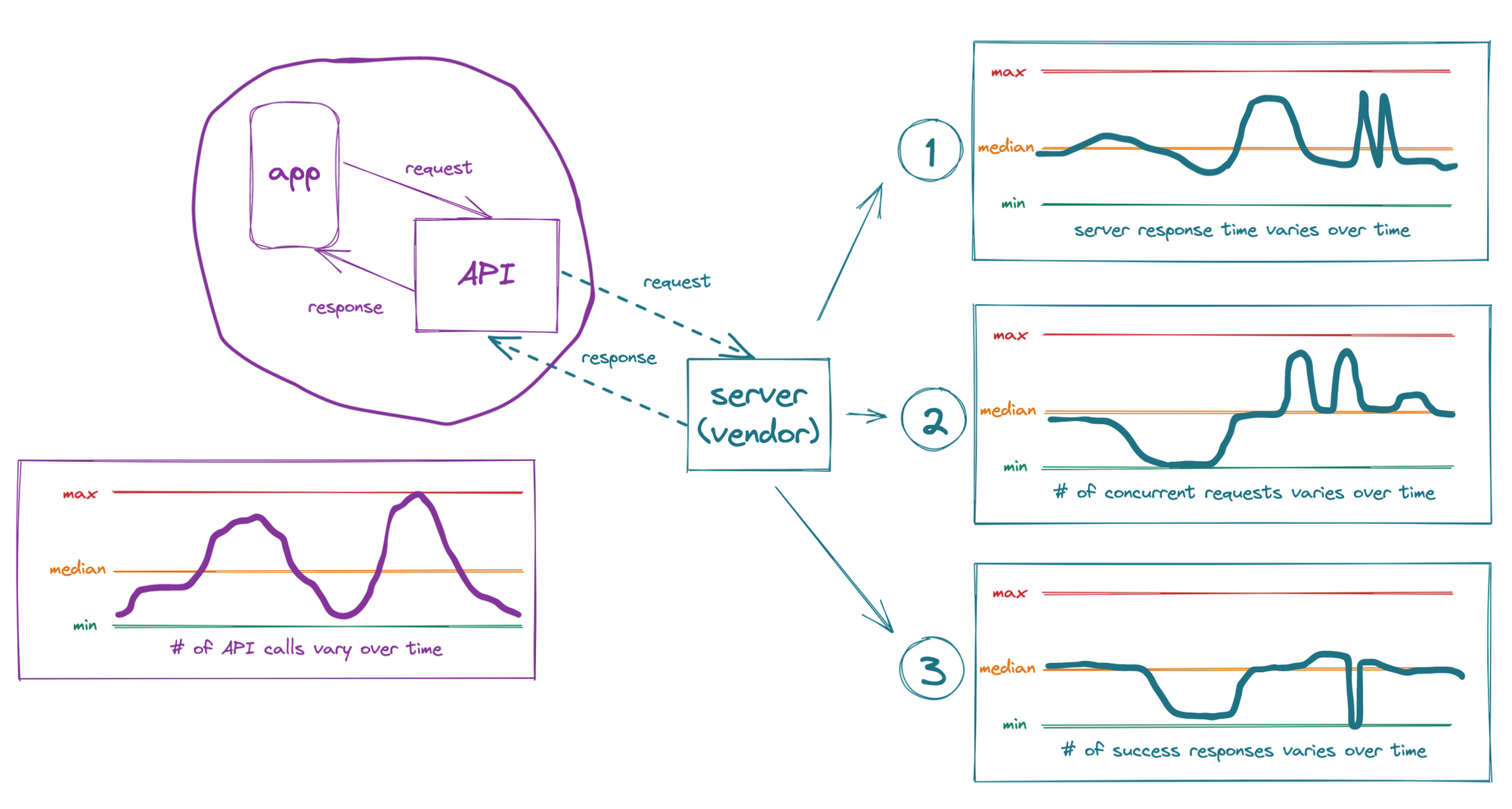
After a lot of back and forth with the vendor, the team realizes that the vendor won't be able to deliver better results anytime soon. Moving to a new vendor won't be possible at this stage as it is a strategic move that will require restarting a complex negotiation process and a new technical implementation, and a migration process that may take years.
3. An Adaptive Design Solution
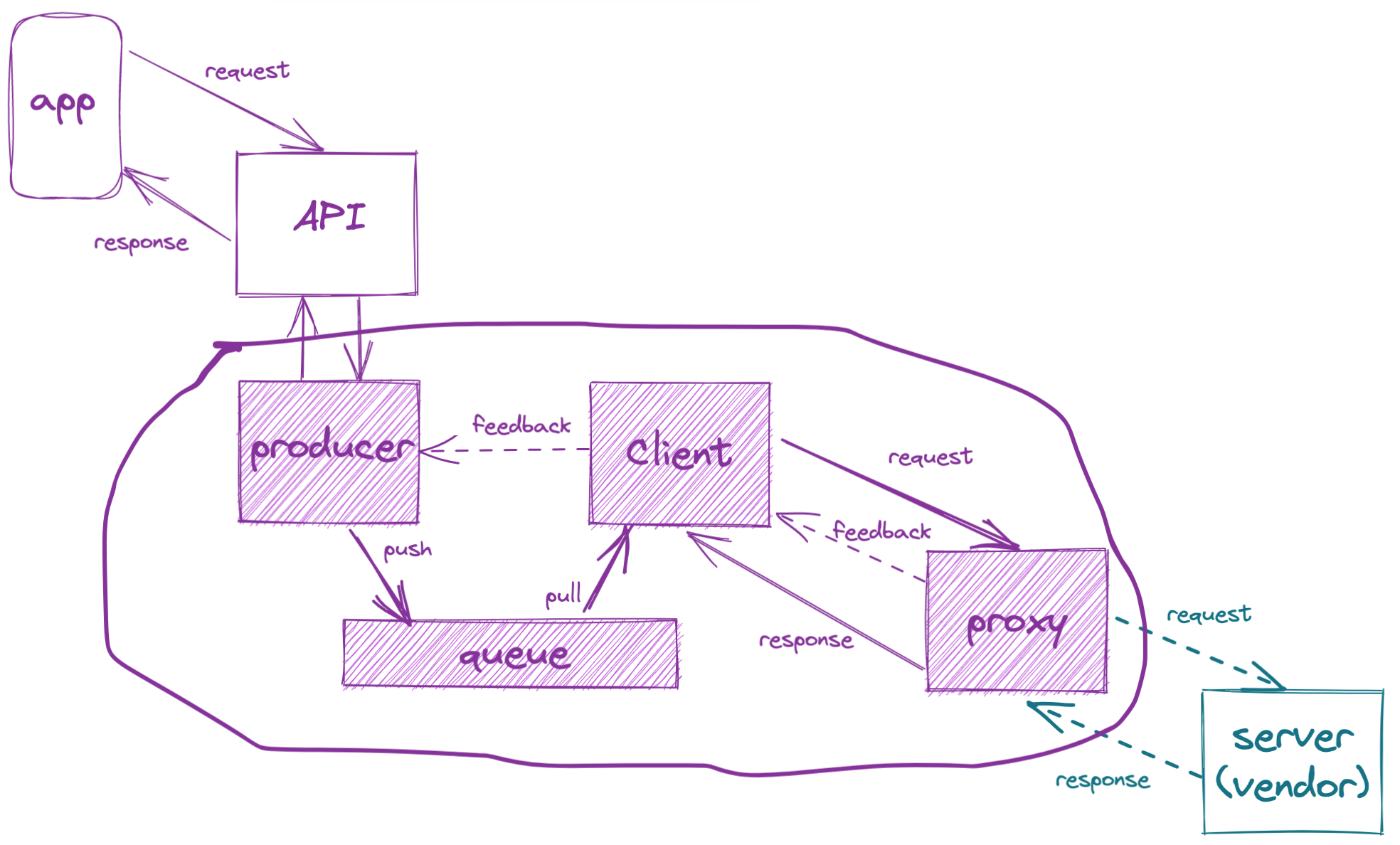
One potential solution would be to loosen up the synchronous and static design of the system and introduce a few components starting from the vendor to the user:
- A forward proxy to act as a broker between the two parties. Aside from transparent communication to and from the server, implementing basic resiliency patterns (i.e. simple retry, timeout circuit breakers, or even fallbacks to local caches for certain cases), the proxy's other important role is to provide telemetry to the client about the server's performance.
- A client which will own the communication strategy with the vendor
- A queue which will act as ephemeral storage for queuing requests
- A producer service which is responsible for brokering requests for the API. It allows the API to focus on serving the App while producing requests to the client on its behalf.
- A telemetry solution not shown for simplicity. Instead the dotted arrows show the feedback loops enabled by this telemetry.
3.1. The Approach
Let's start with a workbench test. First, we will simplify the system by temporarily ignoring the App and the API and focus on the producer which can be artificially configured to continuously generate requests that are uniformly distributed at RAPI=max measured API traffic (requests for second). This will ensure that traffic peaks are covered. In this context, the producer is greedy: I must produce at RAPI rate at all times and at all cost. I will also accept anything within the range [min, RAPI] if necessary but I will continue pushing for RAPI over time. I won't give up.
Second, let's develop a client that is smart enough to negotiate with the producer: ok, I will help you, producer, but I will let you know when you might want to slow things down or speed things up. I will take care of the rest.
Third, let's implement a queue which will provide a back-pressure absorbent layer between the client and the producer so that shockwaves from the vendor server never reach the API. We'll assume the queue in this example has much higher throughput than the production rate RAPI.
Finally, what is left is to figure out how to implement the smart client. Let's just consider the three SLAs being broken one at a time.
3.1.1. Scenario 1: Changes to server rate or concurrent requests limits
Server and concurrency limits should not have any effect on the client system as long as server rate Rs and server concurrency rate Ps (P for pool size) are such that
PAPI << Ps and RAPI << Rs
Otherwise, the server will begin responding to impacted requests with a typical 429/TooManyRequests response code. (Remember we are using simple HTTP for this example). The client must put these requests back to the queue for reprocessing and then signal the producer to slow down if re-enqueuing reaches a threshold. Given, the client doesn't know what the new viable rate must be, the feedback for the producer is intentionally open. The producer then lowers the ceiling of the [min, RNEW] where
RNEW = 0.75 x RAPI
It continues lowering the rate recursively until the client's feedback is no longer negative. The producer must also memorize the new ceiling RNEW and attempt to raise it at a less frequent interval given that client signal is positive, following an exponential curve that will continuously approach RAPI again. This is important to help the producer to make but continuous changes to its production plan rather than reacting dramatically to feedback which can result in calibrating difficulties for the producer-client operation.
3.1.2. Scenario 2: Changes to response time
The way to make up for lost time per request is to send more requests in parallel, thus increasing computational costs. Little's Law can help figure out how many. It says that, given a stationary system
L = λW where
L - is long-term average of number of customers in a stationary system
λ - is the long-term average effective arrival rate
W - is the average time the customer spends in the system
Note a couple of important things. This formula talks about averages. This formula isn't computer-science specific. It may as well apply to people waiting to enter a large football stadium with multiple lines and gates. We can redefine it to fit our problem.
a customer is a client request
arrival rate is production rate
time spent in system is request time
then we can rewrite the relationship above as
PAPI = RAPI T
where
PAPI - avg # concurrent requests which defines a client "thread" pool size P *
RAPI - the average production rate
T - the response time that includes server, proxy, and client time
* Given our scale context, it's likely by "thread" here we mean a type of virtual thread. We are talking about potentially hundreds or even thousands of threads on a web server which are only possible using reactive/async solutions and not native threads. In the implementation example below I have used goroutines to achieve and control concurrency for this purpose.
With this approach we have enabled a way to increase the number of concurrent threads to PAPI maintain RAPI as long as PAPI << Ps from scenario 1 is true.
3.1.3. Scenario 3: Changes to response success rate
An accumulator on the client tracks request failure count. If this average rises above a critical predetermined threshold, the client can do a few things:
- can alert the producer to slow down, just like in scenario 1, because the root cause of functional issues is often related to saturation-related conditions
- alert the team (this is where manual intervention is finally needed)
- retry the failed requests by re-enqueueing and serve cached data along with proper messaging for the user
4. An Example Implementation
How does this type of design work in practice? How can one build such a system?
For demo purposes I implemented a distributed system example with Golang so that I could take advantage of Goroutines, a type of lightweight virtual thread solution that comes with the native Go runtime. However, similar implementations can be delivered with other reactive/async architectures in any technology stack. This solution spins up several services which are already pre-configured to talk to one another on localhost.
You can find the entire source code here: https://github.com/georgetheka/adaptive-architecture
In order to test the system just build and run using this steps:
make install
make build
make runIn order to stop the system use:
make stopFor more details see the README file:
 georgetheka
georgetheka5. Results
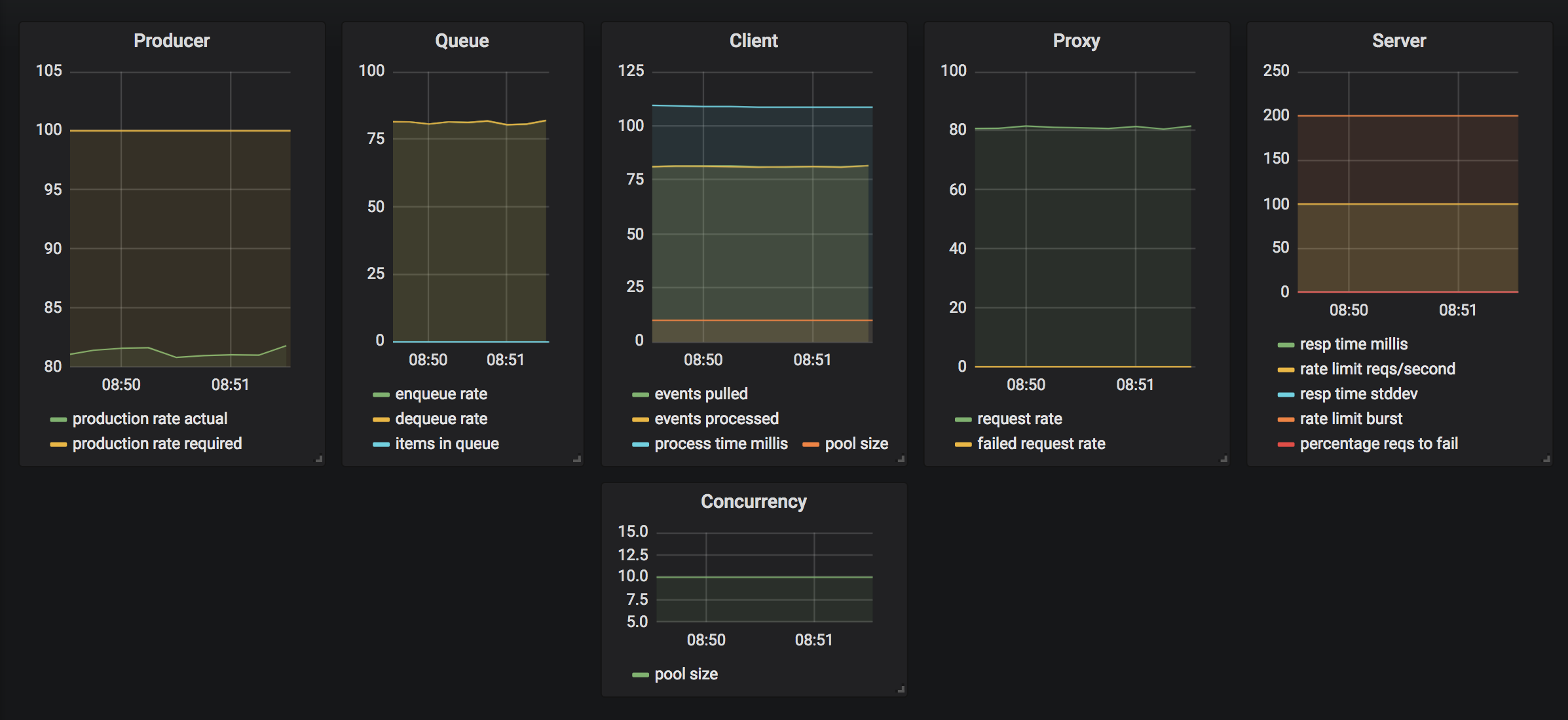
Fig. 1 shows a the stable system running with the following characteristics:
Producer Rate: RAPI = 100 requests / second
Thread Pool Size: PAPI = 10 (goroutines)
Response Time AVG: T = 100ms
The actual production rate is about 85 requests / second. It means the system is working at about 85% efficiency due to some loss in synchronization and optimization.
5.1. Scenario 1: Changes to server rate or concurrent requests limits
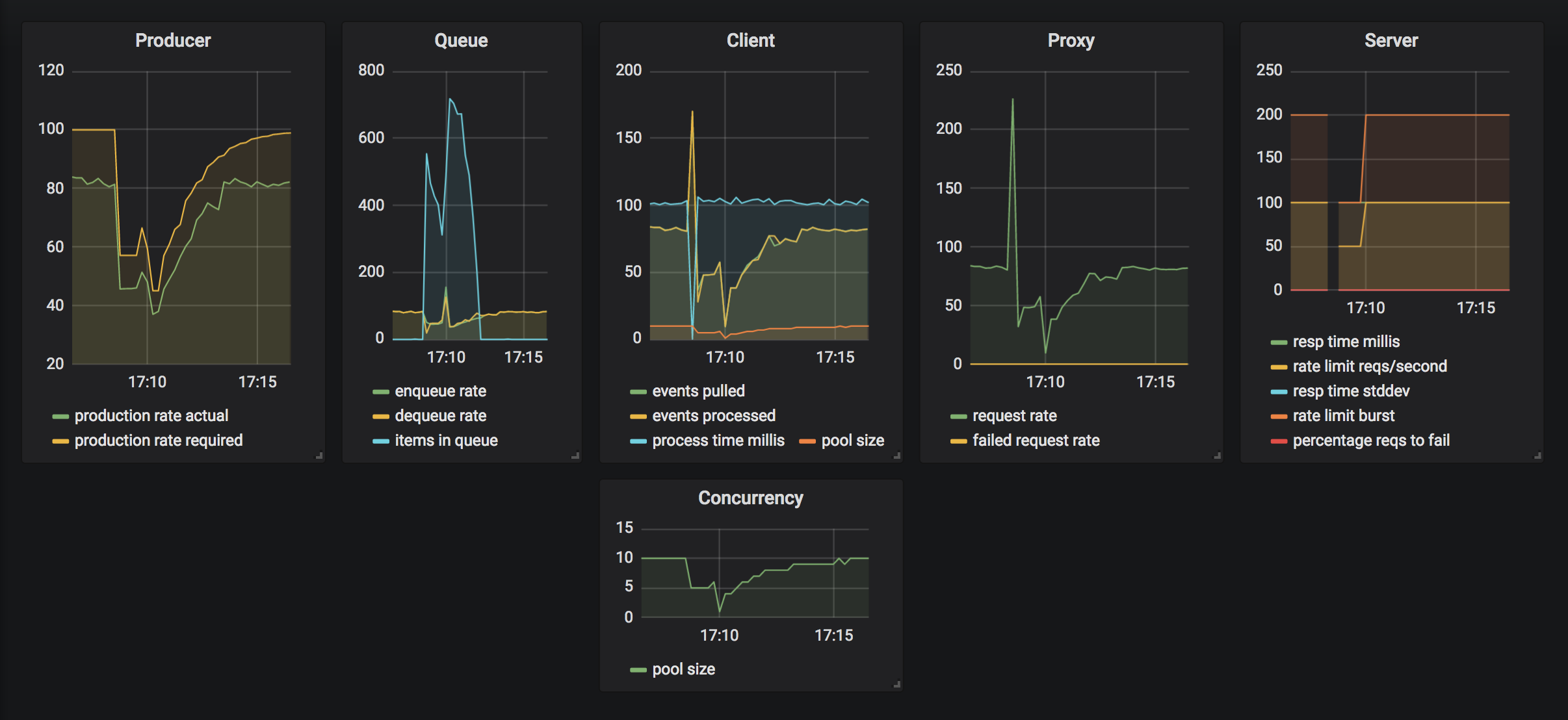
What if the rate limit suddenly dropped below the level agreed upon, to say only 50% of the required rate? We can reduce the rate in half by calling this endpoint:
curl http://localhost:7777/reduceratelimitand then we can increase the rate limit by calling this endpoint:
curl http://localhost:7777/increaseratelimitThe client notices that too many requests are being returned due to the low rate limit and it absorbs the back-pressure from the server by re-enqueuing the events and notifying the producer to slow down. Producer then slows by guessing a lower rate limit and over time continues to adjust its rate up or down based on the client input. Once the client signals that the server rate limit stabilizes, the producer gradually increases the throughput to match the desired state. At the same time, the client scales down resources as well to re-achieve equilibrium state.
5.2. Scenario 2: Changes to response time
Next, let's simulate a server slowdown by forcing the server to double the response time each time the following server endpoint is called.
curl http://localhost:7777/slowdown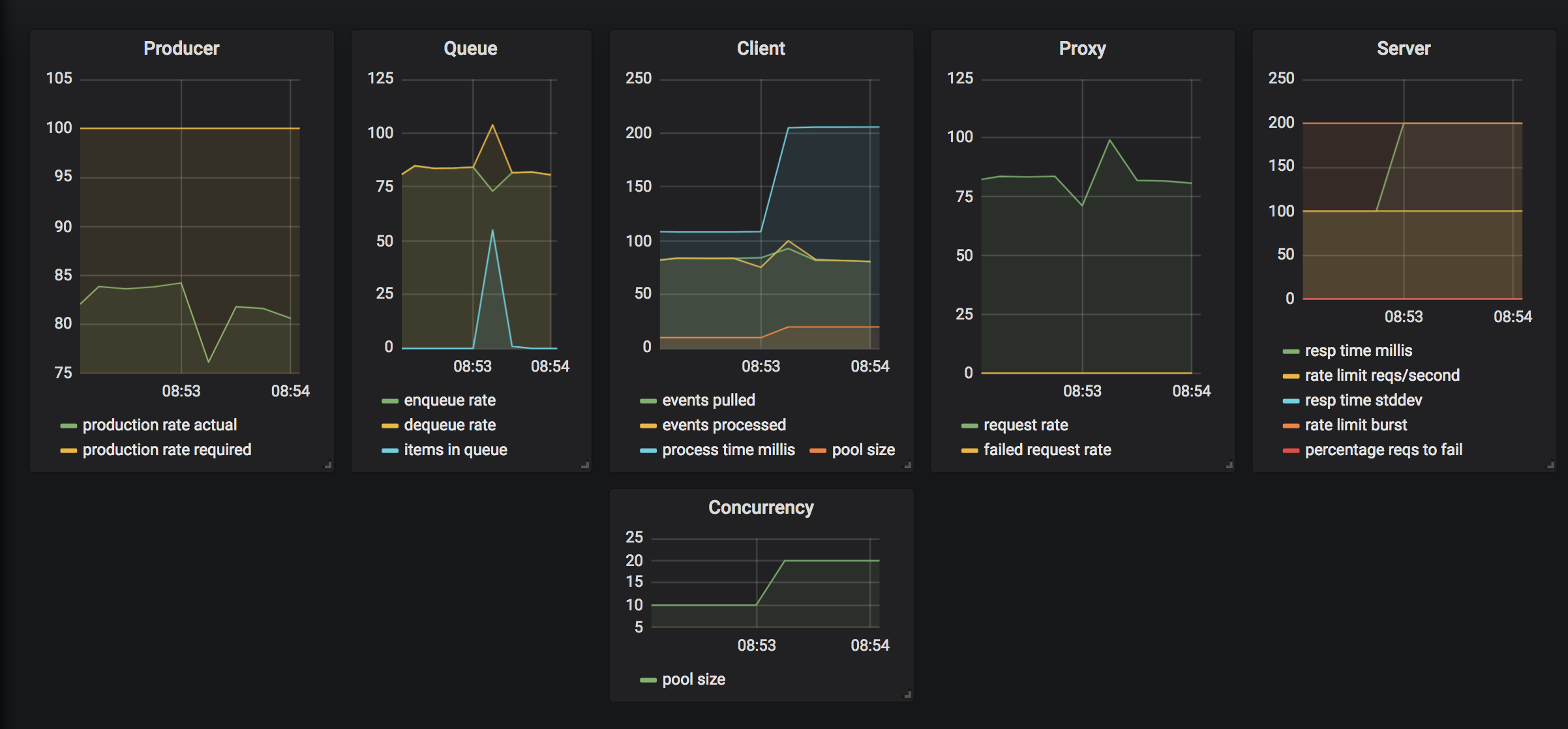
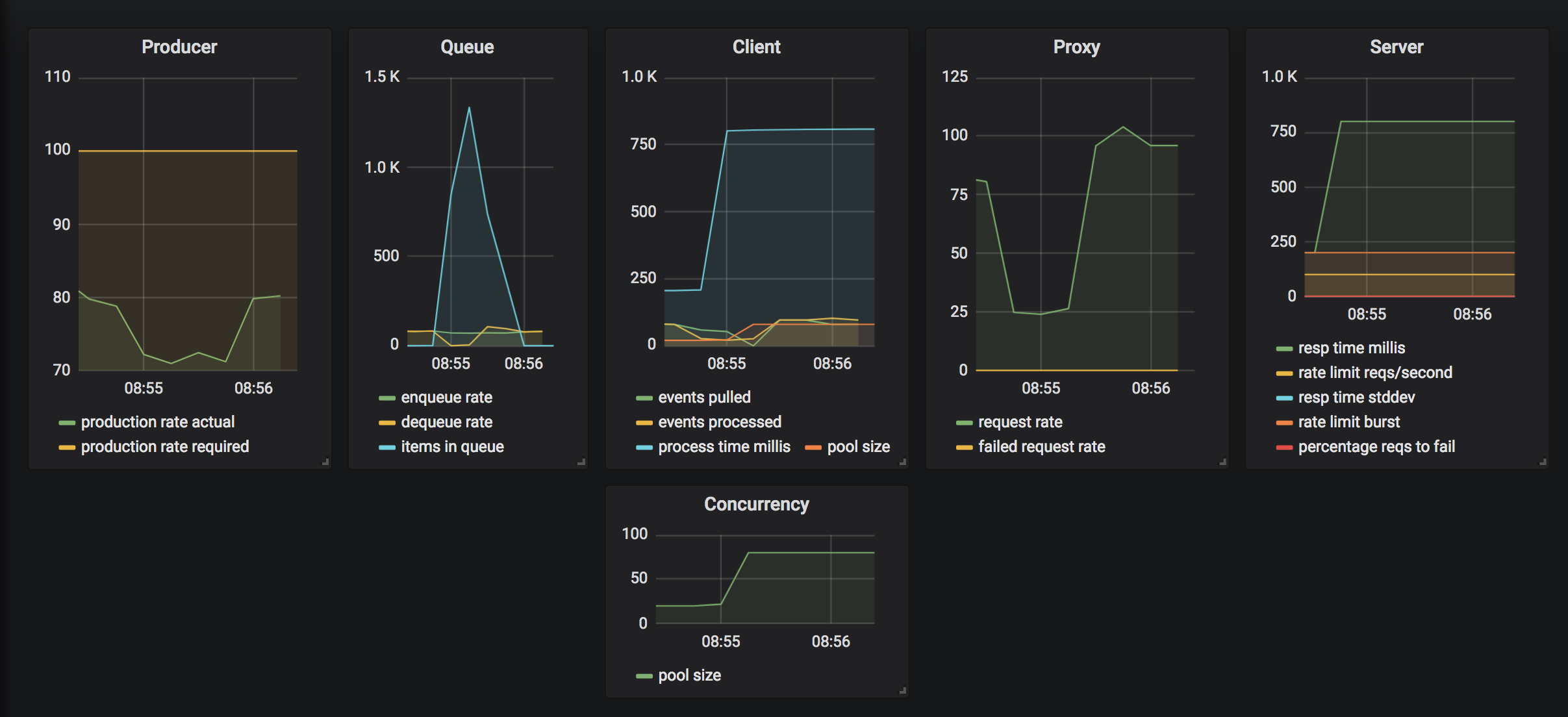
A few moments later, the system finds a new equilibrium point maintaining consistent throughput at the previous efficiency level but having acquired more resources (number of parallel workers) therefore at a higher but optimal cost for the new conditions. Notice the new pool size has self adjusted from 10 to 100 (in actuality ~90).
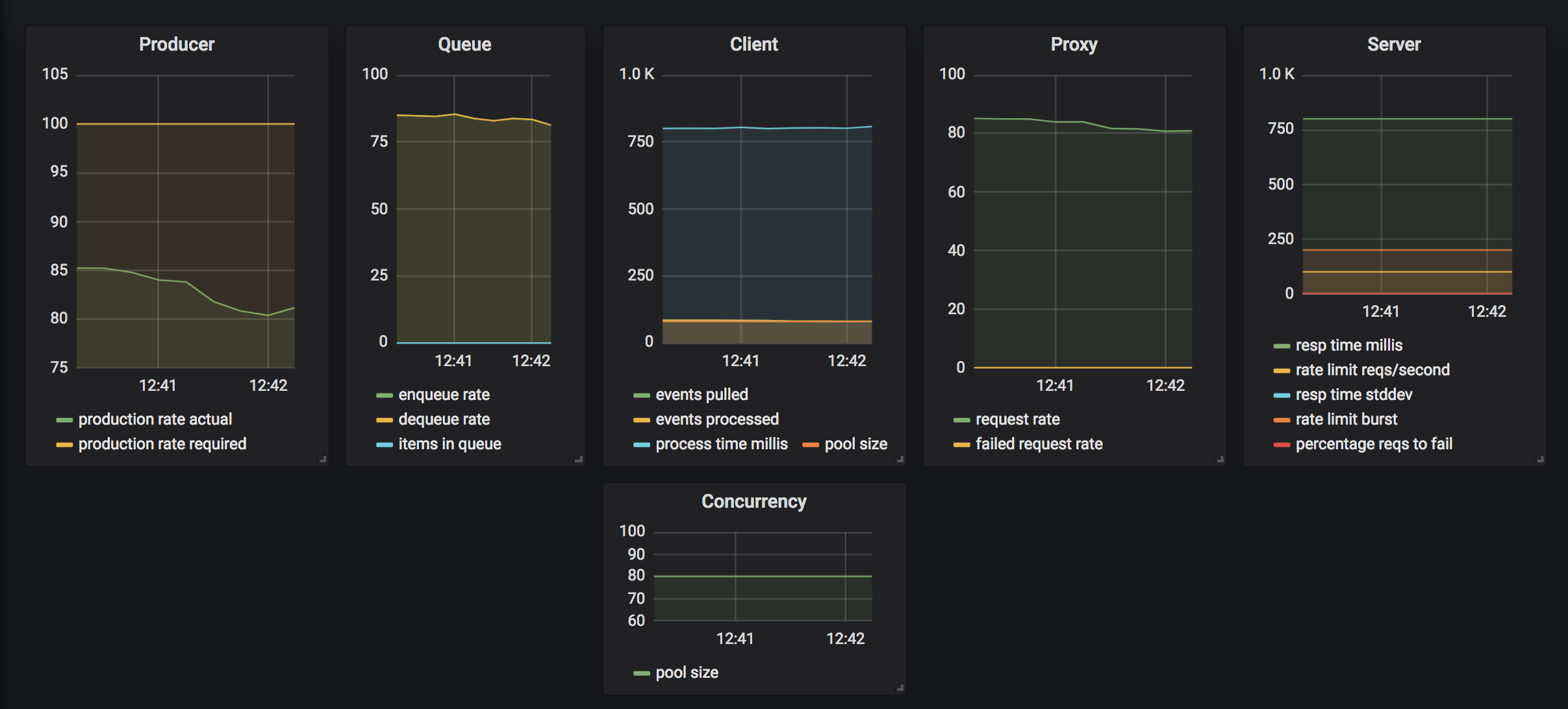
Now, let's speed up the vendor system again. The following endpoint will cut the response time in half for every call. The system will then respond by recalibrating itself by reducing number of resources back to minimal levels.
curl http://localhost:7777/speedup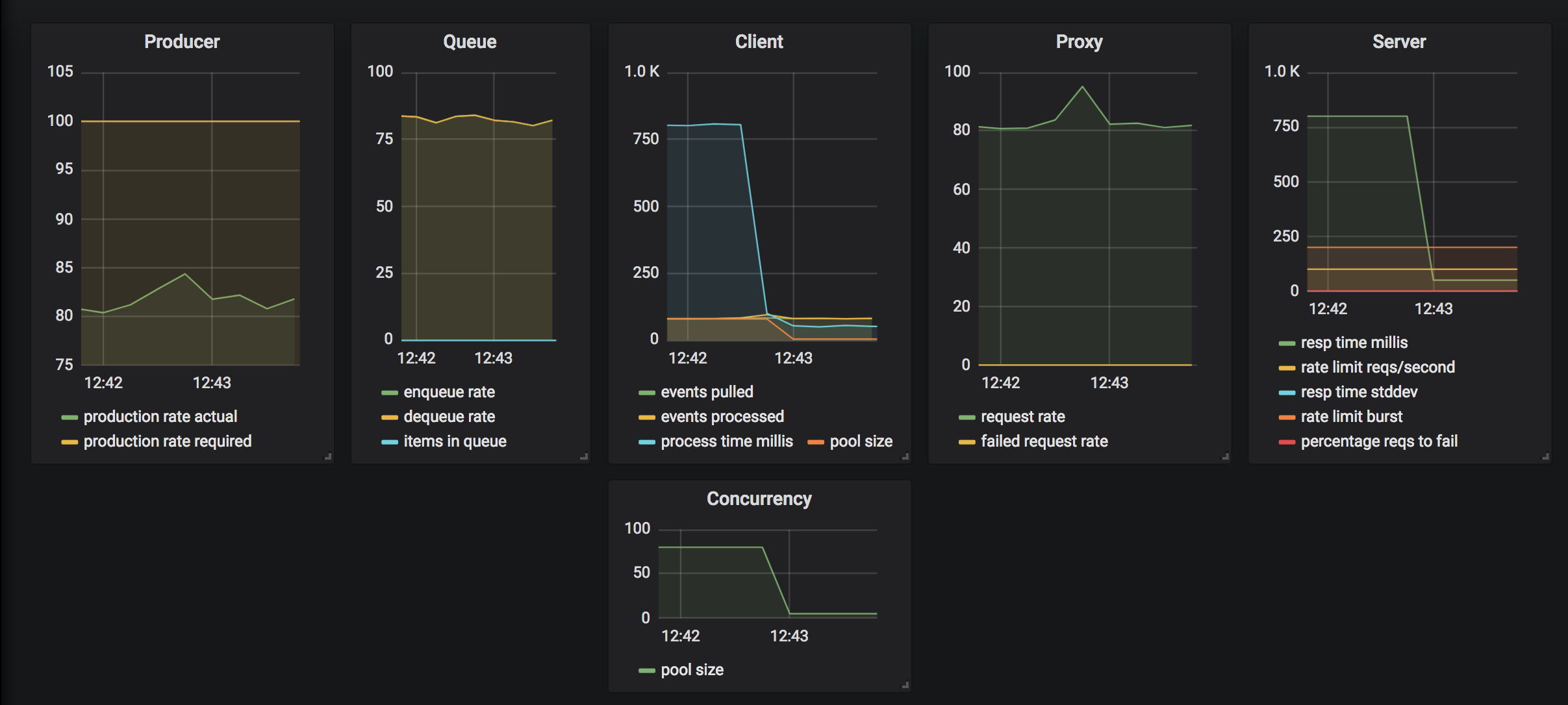
5.3. Scenario 3: Changes to response success rate
The client is observing the number of failures and once a certain threshold is reached several things can happen:
- an alert is sent to the team (not implemented)
- the producer can be alerted to slow down (not implemented)
- errors can be re-enqueued for a second try (not implemented)
Increase the probability of requests to fail randomly and uniformly using the following endpoint:
curl http://localhost:7777/control?percentage_reqs_fail=20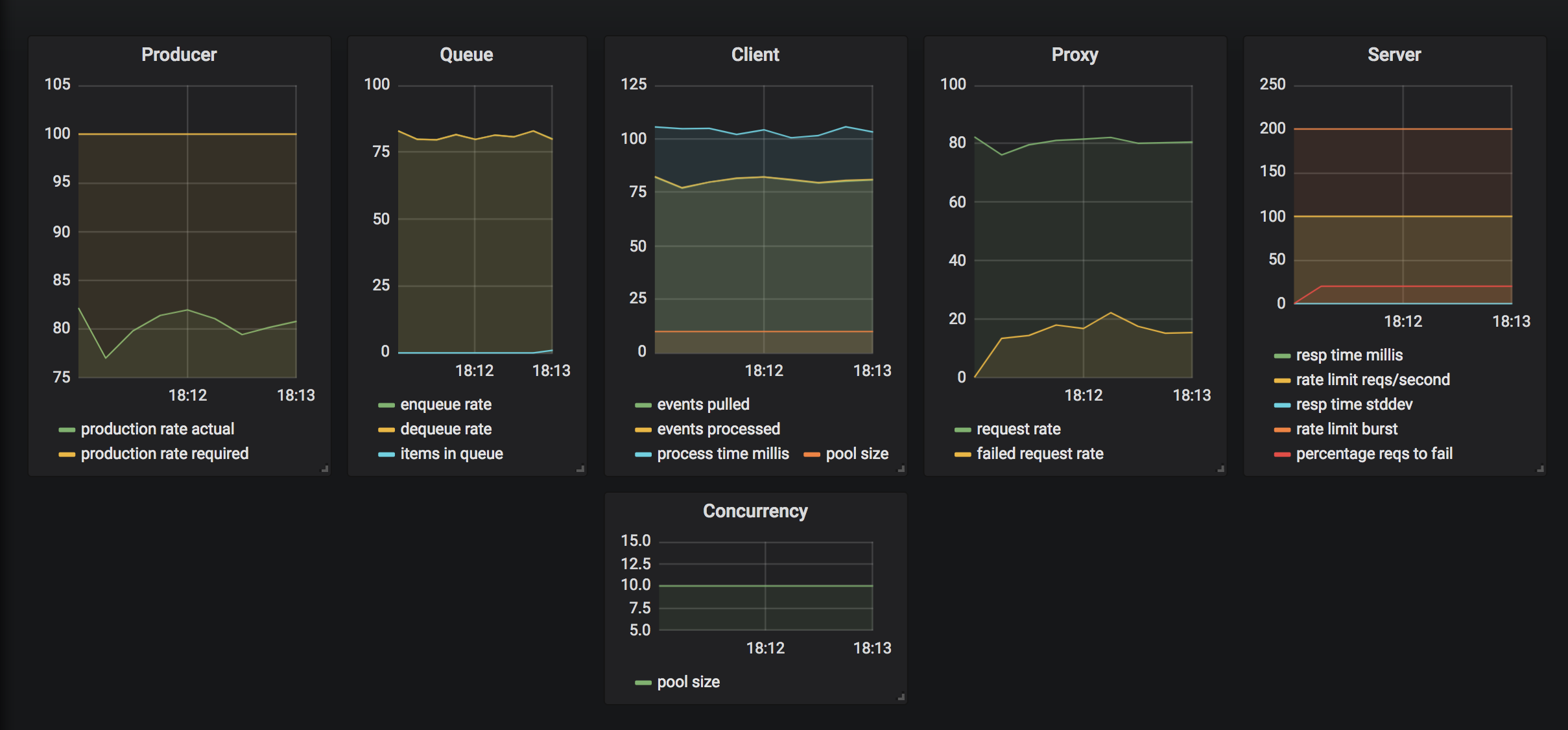
5.2. Wait one second
Hold on. I understand that the dynamics between the client <> producer are now changing to automatically adapt to the new conditions. But how does this translate to an improved user experience? For this to happen, additional infrastructure would be needed, not shown in the design. For example, an additional memory cache would be required to track the open state of not-yet-fulfilled app requests. The app itself will need the ability to switch between a sync and an async + polling strategy with an exponential backoff pattern once the API response indicates the result will be delayed. For most active users, an LRU cache could feed a background process that continuously requests and updates info ahead of time.
6. Conclusion
This example strives to demonstrate some ways to design distributed systems that can adapt their performance against external factors when operating at the desired scale.